PEMANFAATAN FUNSI FIND ALL
PEMANFAATAN FUNGSI FIND_ALL
Gunakan library BeautifulSoup untuk mengambil element HTML yang ingin disimpan seperti konten quote, author, tag dengan menggunakan class attribut di kode HTML. Setelah mengetahui class attribut gunakan fungsi find() atau find_all() untuk mengekstrak konten dari halaman website. BeautifulSoup memanfaatkan atribut class / id untuk mengambil data dari halaman web.
#1 Quote
Inspect quote pertama dari Albert Einstein dan dapatkan nama class yang digunakan

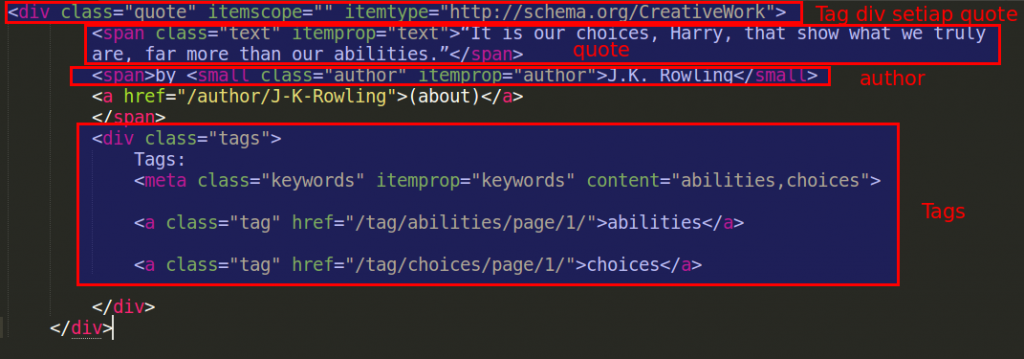
Tag yang digunakan adalah <span> dengan nama classs text
Gunakan library BeautifulSoup dengan fungsi find() untuk mengekstrak quote pertama
Hasilnya

Jika hanya ingin mengambil quote saja tanpa tag HTML tambarkan properti text di akhir fungsi find()seperti ini
quote = soup.find('span', class_='text').text
#2 Author
Tag yang digunakan untuk Author adalah <small> dengan nama class author

Tambahkan kode berikut setelah kode diatas
Hasilya

#3 Tags
Dan terakhir adalah tags dari quote

Untuk element tags agak sedikit lebih rumit karena setiap tags diapit oleh <a> yang berada di dalam <div> sehingga tags harus disimpan ke dalam List
Dibutuhkan fungsi find() untuk mengambil konten <div> dan fungsi find_all() untuk mengambil isi dari <a>
Tambahkan kode berikut untuk mengambil text dari tags yang disimpan ke dalam List

Final Code
Berikut adalah final code untuk scraping single quote

kita telah sukses melakukan web scraping single-quote dari halaman http://quotes.toscrape.com/ dengan library BeautifulSoup di Python. Selanjutnya kita akan mengambil multi-quote dari satu halaman
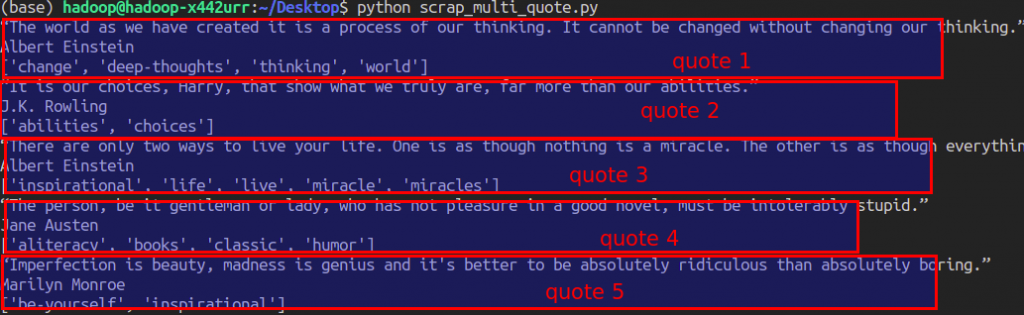
Kalau kita lihat http://quotes.toscrape.com/ pada halaman pertama terdapat 20 quote. Berikut adalah contoh 3 quote-nya

Jika dilakukan inspect element maka diketahui bahwa tag HTML yang digunakan oleh setiap quote adalah sama

Berikut adalah outer HTML dari quote

Bahwa setiap quote berada di tag <div> dengan nama class quote
Di dalam tag <div> baru terdapat tag-tag HTML lainnya untuk menyimpan konten seperti quote, author, dan tags
Berikut adalah satu contoh kode HTML dari satu qoute
Scrap all quotes
Karena setiap quote kode HTML yang digunakan sama gunakan fungsi find_all() untuk mengambil semua konten quote dalam satu halaman
Jika menggunakan fungsi find() hanya quote pertama yang akan diambil (seperti pada materi scraping single quote)
Gunakan tag <div> dengan nama class quote

Setelah mendapatkan konten dari setiap quote selanjutnya setiap quote akan diambil konten text quote, author, dan tags -nya
Untuk memudahkan mengambil konten setiap quote gunakan perulangan.
Note : Silahkan baca materi perulangan di python
Berikut adalah kodenya untuk mengambil setiap elemen di quote menggunakan perulangan
quotes merupakan list dari semua quote yang diambil dengan BeautifulSoup
Setiap iterasi dalam quotes akan diambil konten quote, author, dan tags -nya
Hasilnya adalah
Final Code
Berikut adalah final code untuk web scraping multi-quote dalam di halaman pertama

_all('a', class_='tag')]



Komentar
Posting Komentar